Ana1.3 網站爬蟲實作:抓取XKCD網站
在此節會利用上述兩節所運用到的語法,並且將其予以結合成一個抓取網站中圖片的流程,透過此流程可以將範例網站中圖片依序下載至使用者的本機電腦中。在此節中使用 xkcd.com 為範例網站,來實作該網站的圖片爬蟲。
此圖片爬蟲的概念流程如下:
# 顯示開始訊息
# 設定變數
# while True:
# 連線到網頁及下載內容
# if 網頁已經被下載:
# 取得圖片的網址
# 取得下一個網頁的網址
# if 圖片已經被下載:
# 記錄已經被下載的網頁數量
# else:
# 顯示略過此次下載的訊息
# 隨機暫停1~2秒
# 準備下一個網址
# else:
# 顯示略過此網頁的訊息
# 結束條件1
# if 目前網頁是第1個網頁:
# 表示可能連不上網站的第1個網頁
# break
# else:
# 顯示略過此次的訊息
# pass
# 結束條件2
# if 是否全部讀取:
# if 是否為最後一個網頁
# break
# else:
# if 是否達到抓取數量
# 顯示所抓取的圖片數量
# break
# 顯示結束訊息
- 參考檔案:xkcd_crawler.py
# 匯入模組
import bs4
import os
import os.path
import random
import requests
import time
# 定義函數
def error_message(url="", msg=""):
# 顯示錯誤訊息
print()
print("[!!!]")
if url != "" :
print("There was a problem happened, skip this page:")
print("- {0}".format(url))
print()
if msg != "":
print("Error message:")
print("- {0}".format(msg))
print("[!!!]")
print()
def download_image_from_url(img_url, chunk_size=1024):
try:
r = requests.get(img_url)
r.raise_for_status()
if r.status_code == requests.codes.ok:
file_name = os.path.basename(img_url)
# 儲存檔案
with open(file_name, 'wb') as f:
for chunk in r.iter_content(chunk_size):
return_value = f.write(chunk)
return True
except Exception as e:
pass
error_message(img_url, "The file can not be downloaded.")
return False
def get_page_from_url(page_url):
err_msg = None
try:
# 連接到網站
r = requests.get(page_url)
r.raise_for_status()
if r.status_code == requests.codes.ok:
return r.text
else:
err_msg = "Status code: {0}.".format(r.status_code)
except Exception as e:
err_msg = e
# 錯誤訊息
error_message(page_url, err_msg)
return False
def get_image_url_from_page(page=None):
# 分析網頁
soup = bs4.BeautifulSoup(page, "html.parser")
# 建立圖片網址
img = soup.select('div[id=comic]')
img = img[0]
img_url = 'http:' + img.find('img')['src']
return img_url
def get_prev_url_from_page(page=None):
soup = bs4.BeautifulSoup(page, "html.parser")
# 建立網頁網址
url = soup.select('a[rel="prev"]')
url = url[0]
pre_url = 'https://xkcd.com' + url['href']
return pre_url
def xkcd_crawler(url='https://xkcd.com/', num_crawls=10):
num_crawls = abs(int(num_crawls))
page_index = 0
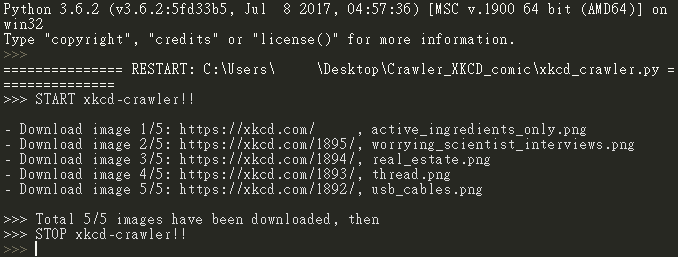
print(">>> START xkcd-crawler!!")
print()
while True:
page = get_page_from_url(url) # 取得網頁內容
if page:
# 取得圖片及下一個網頁的網址
img_url = get_image_url_from_page(page) # 取得圖片的 url
pre_url = get_prev_url_from_page(page) # 取得下一個網頁的 url
# 儲存圖片為檔案
if download_image_from_url(img_url):
page_index += 1
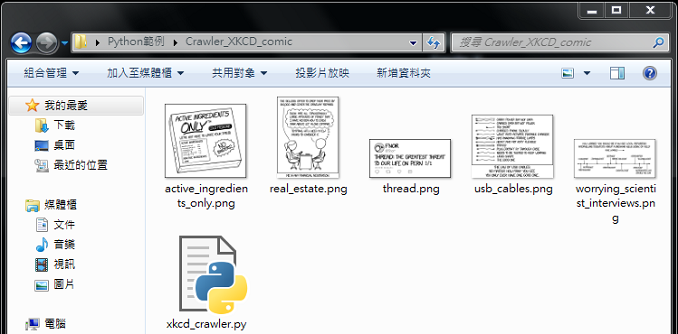
print("- Download image {0}/{1}: {2:<22}, {3}".format(page_index, num_crawls, url, os.path.basename(img_url)))
else:
print("-- Can not download this image: {0}, then".format(img_url))
print("-- Move to next page: {0}".format(pre_url))
# 隨機暫停1~2秒
time.sleep(round(random.uniform(1, 2), 1))
# 準備下一個網址
url = pre_url
else:
print("-- Can not connect to this page: {0}, then".format(url))
# 結束條件1
if page_index == 0:
break
else:
print("-- Skip this page: {0}".format(url))
print()
pass
# 結束條件2
if num_crawls == -1: # -1: 表示全部讀取
if url.endswith('#'): # 表示最後一個網頁
print()
print(">>> Total {0} images have been downloaded, then".format(page_index))
break
else:
if page_index == num_crawls: # num_crawls: 抓取固定數量
print()
print(">>> Total {0}/{1} images have been downloaded, then".format(page_index, num_crawls))
break
print(">>> STOP xkcd-crawler!!")
# main函數: 程式起始點
if __name__== "__main__":
xkcd_crawler('https://xkcd.com/', 5)
參考資料
- Beautiful Soup, ♥️
- How to download image using requests
- How to download image using requests
- xkcd.com, ♥️
- Python自動化的樂趣, 第十一章, Al Sweigart 著、H&C 譯, 碁峰, ♥️