Ana2.2 社群網站爬蟲實作:抓取Facebook粉絲專頁
在此節中透過圖形 API 測試工具來實作及測試Facebook粉絲專頁爬蟲,此爬蟲會抓取特定臉書粉絲專頁上某一個時間之內的貼文時間、內容、圖片附件及取得螢幕截圖。
安裝模組
使用 pip 安裝相關模組。
pip install Pillow
pip install python-docx
pip install selenium
此Facebook粉絲專頁爬蟲的概念流程如下:
# 顯示開始訊息
# 設定變數
try:
# 使用沒有圖形介面的瀏覽器,例如:Headless模式的PhantomJS瀏覽器
while True:
# 連線到特定的Facebook粉絲專頁及下載貼文內容
if 貼文已經被下載:
# 取得post的主要資料
# 儲存post到word檔中
# 檢查是否有下一頁
else:
# 顯示錯誤訊
# 關閉瀏覽器
except Exception as e:
# 顯示錯誤訊息
# 顯示結束訊息
此爬蟲的參數設定。
- 參考檔案: parameter.txt
access_token,xxxxx
node_id,1356367907787271
since,2017-11-08T08:00:00
until,2017-11-08T17:00:00
- 參考檔案:facebook_crawler.py
# coding=utf-8
# 匯入模組
import bs4
import docx
import os
import os.path
import random
import requests
import sys
import time
from docx.enum.table import WD_TABLE_ALIGNMENT
from docx.shared import Cm, Pt
from PIL import Image
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 定義變數
NON_BMP_MAP = dict.fromkeys(range(0x10000, sys.maxunicode + 1), 0xfffd)
# 定義函數
def load_parameter(filename="parameter.txt"):
param = dict()
with open(filename, "r", encoding="utf-8") as f:
for line in f.readlines():
line = line.strip(" \t\r\n")
key, value = line.split(",")
param[key] = value
return param
def generate_fanpage_url(param):
node_id = param["node_id"]
since = param["since"]
until = param["until"]
prefix = "https://graph.facebook.com/v2.10/{0}".format(node_id)
field = "?fields=posts.since({0}).until({1}){2}".format(since, until, "{created_time,message,id,attachments}")
token = "&access_token={0}".format(param['access_token'])
return prefix + field + token
def generate_thumbnail_image(img):
try:
# 以寬度縮圖
# img_width, img_height = img.size
thumbnail_width = 450
thumbnail_height = 600
if img.size[0] > thumbnail_width:
img.thumbnail((thumbnail_width, img.size[1]))
# 以高度縮圖
if img.size[1] > thumbnail_height:
img.thumbnail((img.size[0], thumbnail_height))
except Exception as e:
print("[ERR] {0}".format(e))
return img
def open_browser(type="firefox"):
if type == "chrome":
options = webdriver.ChromeOptions()
options.add_argument("--disable-infobars")
# options.add_argument("--start-maximized")
driver_path = r"C:\Users\xxxxx\AppData\Local\Programs\Python\Python36\selenium\webdriver\chrome\chromedriver.exe"
browser = webdriver.Chrome(executable_path=driver_path, chrome_options=options)
elif type == "firefox":
binary_path = webdriver.firefox.firefox_binary.FirefoxBinary(r"C:\Program Files\Mozilla Firefox\firefox.exe")
driver_path = r"C:\Users\xxxxx\AppData\Local\Programs\Python\Python36\selenium\webdriver\firefox\geckodriver.exe"
browser = webdriver.Firefox(firefox_binary=binary_path, executable_path=driver_path)
else:
os.environ['no_proxy'] = '127.0.0.1'
service_args = []
service_args.append('--disk-cache=yes')
service_args.append('--ignore-ssl-errors=true')
# service_args.append('--load-images=no')
driver_path = r"C:\Users\xxxxx\AppData\Local\Programs\Python\Python36\selenium\webdriver\phantomjs\bin\phantomjs.exe"
browser = webdriver.PhantomJS(executable_path=driver_path, service_args=service_args)
browser.maximize_window()
return browser
def get_data_from_fanpage(url):
err_msg = ""
data = None
# 從粉絲專頁上取得資料內容
try:
r = requests.get(url)
r.raise_for_status()
if r.status_code == requests.codes.ok:
data = r.json()
else:
err_msg = r.status_cod
except Exception as e:
err_msg = e
# 如果有取得資料時,則回傳資料
if data:
if (len(data) == 1) and ('id' in data):
print("[ERR] There is no posts to be processed at this time-interval.")
# No posts case: only 'id' in posts
# {
# "id": "1356367907787271"
# }
elif 'error' in data:
print("[ERR] {0}, {1}".format(data['error']['type'], data['error']['message']))
# Error message
# {
# "error": {
# "message": "Error validating access token: Session has expired on Monday, 09-Oct-17 01:00:00 PDT. The current time is Monday, 09-Oct-17 01:26:16 PDT.",
# "type": "OAuthException",
# "code": 190,
# "error_subcode": 463,
# "fbtrace_id": "Fq8V9WBsWO9"
# }
# }
else:
return data
else:
print("[ERR] {0}".format(err_msg))
# all errors will come here to return False
return False
def get_image_from_url(img_url, img_path="image.jpg", chunk_size=1024):
err_msg = ""
try:
r = requests.get(img_url)
r.raise_for_status()
if r.status_code == requests.codes.ok:
with open(img_path, "wb") as f:
for chunk in r.iter_content(chunk_size):
return_value = f.write(chunk)
return True
else:
err_msg = r.status_cod
except Exception as e:
err_msg = e
print("[ERR] {0}".format(err_msg))
# all errors will come here to return False
return False
def save_posts_to_word(param, posts, page_index, browser):
doc = None
dirname = "image\\"
filename = "fuck-you-sir_{0}.docx".format(param["until"].split("T")[0])
tmp_path = "tmp.png"
# 檢查資料夾是否存在
if not os.path.isdir(dirname):
os.mkdir(dirname)
# 開啟word檔
if page_index == 1:
doc = docx.Document()
doc.styles['Normal'].font.size = Pt(11)
else:
doc = docx.Document(filename)
# 寫入post資料到word檔
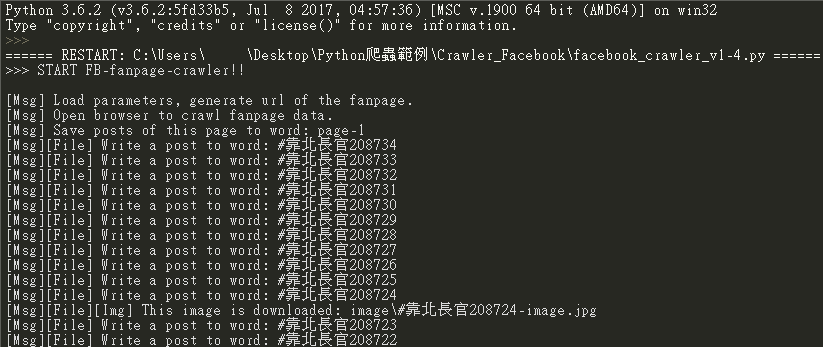
print("[Msg] Save posts of this page to word: page-{0}".format(page_index))
for p in posts["data"]:
# post資料內容: created_time, title, message, page_url, page_id, story_id
ctime = p["created_time"].split("T")
ctime = "{0} {1}".format(ctime[0], ctime[1].split("+")[0])
message = p["message"].translate(NON_BMP_MAP)
title = message[0:message.find("\n")].translate(NON_BMP_MAP)
page_id, story_id = p["id"].split("_")
post_url = "http://www.facebook.com/permalink.php?story_fbid={0}\n&id={1}".format(story_id, page_id)
# ----------------------------------------------------------------------------------------------------
# 建立表格
print("[Msg][File] Write a post to word: {0}".format(title))
table = doc.add_table(rows=6, cols=2, style="Light Shading")
table.alignment = WD_TABLE_ALIGNMENT.CENTER
table.cell(0, 0).text = str("標題")
table.cell(0, 1).text = str(title)
table.cell(1, 0).text = str("時間")
table.cell(1, 1).text = str(ctime)
table.cell(2, 0).text = str("訊息")
table.cell(2, 1).text = str(message)
table.cell(2, 1).add_paragraph()
table.cell(3, 0).text = str("網址")
table.cell(3, 1).text = str(post_url)
table.cell(4, 0).text = str("分析")
table.cell(4, 1).add_paragraph()
table.cell(4, 1).add_paragraph()
table.cell(5, 0).text = str("附件")
# 設定表格Cells的寬度
for row in table.rows:
row.cells[0].width = Cm(1.5)
row.cells[1].width = Cm(16)
# ----------------------------------------------------------------------------------------------------
# 檢查是否附加多個影像檔及下載
if "attachments" in p:
table.cell(5, 1).text = str("如附件所示")
doc.add_page_break()
# 建立影像檔連結清單
img_list= []
if "subattachments" in p["attachments"]["data"][0]:
img_index = 1
for sp in p["attachments"]["data"][0]['subattachments']['data']:
img_url = sp["media"]["image"]["src"]
img_path = "{0}{1}-image{2}.jpg".format(dirname, title, img_index)
img_list.append((img_url, img_path))
img_index += 1
else:
# 僅有單一影像檔
img_url = p["attachments"]["data"][0]["media"]["image"]["src"]
img_path = "{0}{1}-image.jpg".format(dirname, title)
img_list.append((img_url, img_path))
# 下載及儲存影像檔
doc.add_paragraph("附件:")
for img_url, img_path in img_list:
if get_image_from_url(img_url, img_path, 8192):
print("[Msg][File][Img] This image is downloaded: {0}".format(img_path))
# 建立縮圖及加入docx檔中
img = Image.open(img_path)
img = generate_thumbnail_image(img)
img.save(tmp_path)
doc.add_picture(tmp_path)
else:
# Error messages are already shown in get_image_from_url()
pass
doc.add_page_break()
else:
table.cell(5, 1).text = str("無附件")
doc.add_page_break()
# ----------------------------------------------------------------------------------------------------
# 網頁截圖
img_path = "{0}{1}-screenshot.png".format(dirname, title)
try:
# 連線到post_url
browser.get(post_url)
browser.execute_script("document.body.style.zoom='150%'")
# 定位post位置
element = WebDriverWait(browser, 60, 0.1).until(EC.presence_of_element_located((By.ID, "stream_pagelet")))
# element = browser.find_element_by_class_name("fbUserStory")
# element = browser.find_element_by_id("stream_pagelet")
# 處理div視窗使其display='none'
try:
browser.find_element_by_id("expanding_cta_close_button").click()
browser.execute_script("document.getElementById('u_0_e')[0].style.display='none';")
except:
pass
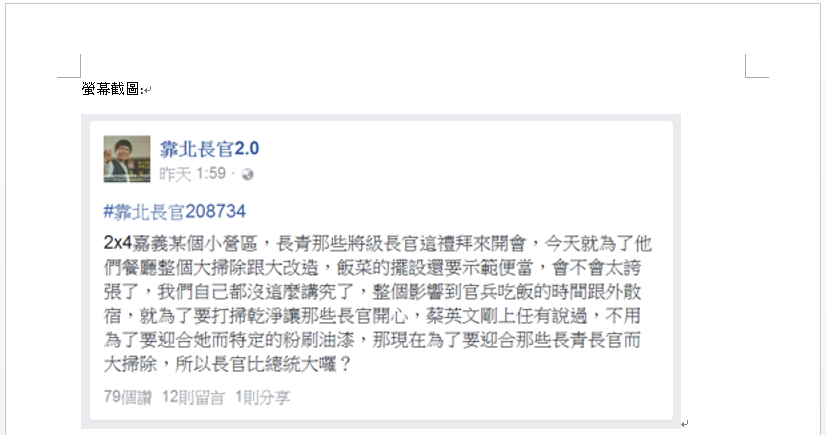
doc.add_paragraph("螢幕截圖:")
browser.save_screenshot(img_path)
except Exception as e:
doc.add_paragraph("螢幕截圖(部份):")
browser.save_screenshot(tmp_path)
print("[ERR] {0}".format(e))
# 截取po文部份
img = Image.open(img_path)
left = element.location["x"] + 97 - 10
top = element.location["y"] + 75 - 10
right = left + element.size['width'] * 1.5 + 20
bottom = top + element.size['height'] * 1.5 + 20
img_crop = img.crop((left,top,right,bottom))
img_crop.save(img_path)
# 縮圖
img = generate_thumbnail_image(img_crop)
img.save(tmp_path)
doc.add_picture(tmp_path)
doc.add_page_break()
# 移除暫存檔
os.remove(tmp_path)
# 調整頁面邊界
for sec in doc.sections:
sec.top_margin = Cm(2)
sec.bottom_margin = Cm(2)
sec.left_margin = Cm(2)
sec.right_margin = Cm(2)
# 儲存docx檔
doc.save(filename)
def fanpage_crawler():
print(">>> START FB-fanpage-crawler!!")
print()
print("[Msg] Load parameters, generate url of the fanpage.")
param = load_parameter("parameter.txt")
page_index = 1
page_url = generate_fanpage_url(param)
print("[Msg] Open browser to crawl fanpage data.")
try:
# 使用Headless模式的PhantomJS瀏覽器
browser = open_browser(type="phantomjs")
while True:
posts = get_data_from_fanpage(page_url)
if posts:
# 取得主要資料
if "posts" in posts:
posts = posts["posts"]
# 儲存posts到word檔
save_posts_to_word(param, posts, page_index, browser)
# 檢查是否還有下一頁
if "next" in posts["paging"]:
print("[Msg] Posts of this page have been processed, then move to next page.")
print()
page_url = posts['paging']['next']
page_index += 1
else:
print("[Msg] All posts have been processe.")
break
else:
# Error messages are already shown in get_data_from_fanpage()
break
# 關閉瀏覽器
browser.quit()
except Exception as e:
print("[ERR] {0}".format(e))
print()
print(">>> STOP FB-fanpage-crawler!!")
# main函數: 程式起始點
if __name__== "__main__":
fanpage_crawler()